解读斯诺登文件(第五部分)
转载自:https://libroot.org/posts/going-through-snowden-documents-part-5/
元数据泄露
我们使用各种工具分析了所有已发布的PDF文件元数据。其中最重要的发现是两份关于美国国家安全局(NSA)间谍中心的文档存在信息删减失败的情况。PDF版本元数据揭示了文档中原本应该删除的整段内容。这一发现已在前文中提及。虽然我们认为这是一项发现此前未知信息的重要成果,但我们原本希望能够发现更多重大发现。
事实上,总体而言,记者们在编辑文件和确保文件元数据不会泄露任何重要信息方面做得非常出色。
(信息披露说明:在本次分析过程中,我们发现了一些本应被隐去但仍然可见的美国国家安全局特工用户名和目标标识符(例如IP地址和电子邮件地址)。我们选择不重新发布这些信息。我们在此的重点是记录信息隐去失败和元数据泄露的模式。)
以下是我们发现的其他元数据泄露。
美国国家安全局间谍航天器标签
在题为“Menwith收藏资产”的文件中,第二页的航天器图像原本带有黄色文字标签,解释了每个部件的含义。航天器的名称已被涂黑(可能是猎户座或复仇女神?)。
 这是已发布版本的屏幕截图。
这是已发布版本的屏幕截图。
 这是早期版本的屏幕截图,显示了黄色标签。
这是早期版本的屏幕截图,显示了黄色标签。
已移除的标签:
12.7 米收集反射器 2A2100 商用巴士 32.0 米下行链路天线 44x40 MHz 截获频道 5C、Ku、Ka 号角
Target 的电子邮件地址和机器 ID 可见
在题为“2010 年 11 月运营工程”的文档中,第 23 页的屏幕截图显示了版本 1 中的目标电子邮件地址和机器 ID,后来在最终发布的版本中被删除。
目标HTTP标头值和NSA特工用户名可见
这份名为“TDI简介”的文件共有四个PDF版本。在版本1和版本2中,第13页显示了目标网站的HTTP标头值(cookie、URI、referrer),但在版本3和版本4中这些内容已被删除。在版本3中,“youporn”和“reuters”这两个域名在同一页面上被高亮显示,但这些高亮显示(可能是记者添加的)在最终发布的版本4中被删除。
在版本 1 中,第 15 页和第 16 页显示了 NSA 特工的用户名,但在后来的版本中被涂黑了。
装饰图片已移除,截图已模糊处理,监控信息已编辑。
题为“优雅的混乱:收集一切,充分利用一切”的文件有五个 PDF 版本。
- 在版本 1-3 中,首页和末页的页脚背景图像是可见的,但在后来的版本中被移除,可能是因为它显示了人物。
- 在版本 1 和 2 中,第 7 页的屏幕截图没有模糊处理(尽管由于质量问题,文本仍然无法辨认),但在后来的版本中,该屏幕截图被模糊处理了。

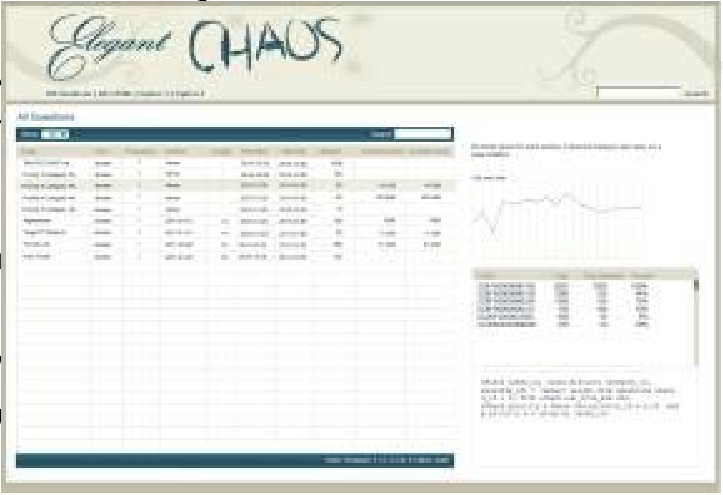
- 在版本 1 和 2 中,第 15 页表格中第一行的主题和描述清晰可见。在版本 3 和 4 中,描述部分被模糊处理。在已发布的版本 5 中,主题和描述均被模糊处理。该行的主题为“Muj Secrets”,描述为“每天在信号灯上检测到 Muj Secrets 流量,即可获得 1000 积分”。Muj Secrets 很可能指的是Mujahedeen Secrets(圣战者秘密)。


已删除文本
在题为“敏感目标授权”的文件中,日期和“任务”字样被删除。原文件可能填写了所有字段,但记者删除了所有已填写的信息,并发布了未填写版本的文件。
 已发表版本。
已发表版本。
 版本 1 显示文本“2008 年 10 月 3 日”和“任务”。
版本 1 显示文本“2008 年 10 月 3 日”和“任务”。
糟糕的编辑
在题为“2010年5月28日移动主题简报”的文件中,我们发现最后一页上有一段被涂黑的文字可以选中。这段文字的内容是:
1• 独立 TERRAIN 用于初始移动开发 - SSE/SMO/COMSAT 接入(SSE 的长期 MVR)。
我们仅在波兰网络安全博客zaufanatrzeciastrona.pl上发现过一处提及此错误编辑的内容。该博客称,“隐藏的片段听起来相当神秘”,并表示“或许有一天会有人能够破译它”。除已报告的内容外,我们在已发布的文档中未发现其他错误编辑。
编辑失败
已发布的文档包含大量未删除的信息(本应删除但最终版本中仍然可见的信息)。最常见的例子是美国国家安全局特工的用户名和目标标识符,例如 IP 地址和电子邮件地址。
以下方法可以展示这些失败的程度。我们对所有已发布的文档进行了OCR扫描,并提取了以常用字符(空格、逗号、句点等)分隔的7个字符的字符串,作为潜在的NSA用户名。过滤掉常见的英文单词后,我们剩下不到1000个候选用户名。然后,我们通过在文档上下文中搜索这些潜在用户名,手动验证了它们的有效性。
我们在不到一个小时的时间里就找到了超过20个美国国家安全局(NSA)特工的用户名。这些NSA用户名(官方名称也称作“ SID ”,即安全标识符)似乎遵循统一的7位字符格式:两个姓名首字母,后跟至多四个姓氏字符,有时还会带有尾随数字。例如,斯诺登的用户名是“ejsnowd”(Edward Joseph Snowden)。
这种统一的用户名格式使得如果你知道特工的姓名,就能猜到他们的用户名;反之,也使得你能够根据用户名部分还原出他们的姓名。存在一种不一致的编辑模式:同一个用户名在同一文档的不同截图中,有的显示为已编辑,有的则显示为可见。由于用户名由两个首字母和四个姓氏组成,攻击者可以将其与已知的美国国家安全局(NSA)人员名单进行交叉比对,根据名字首字母缩小候选人范围,或者通过匹配模式来验证嫌疑特工的身份。这在两个方面都体现了操作安全漏洞:一是NSA的用户名格式过于可预测,二是记者无法始终如一地识别和编辑这些信息。
分析、解剖
我们使用多种工具和脚本来查找元数据泄露、错误的编辑以及通常意义上“不应该存在”的信息。
值得注意的是,尽管我们认为已经获取了几乎所有已发布的文档,但仍可能有遗漏,这些文档可能存在元数据泄露、编辑不当等问题。此外,我们可能拥有文档的其他版本(因为许多不同的组织和个人都重新发布了文档,并且很多人编辑了文件名和元数据),而这些版本并非原始发布版本。
分析范围
我们检查了隐藏图层/可选内容组 (OCG)、注释、表单字段、附件/嵌入文件、版本历史记录以及错误的编辑(例如,可选择文本上的黑框)。一些分析技术过于复杂或误报过多,因此我们没有系统地检查:位于可见页面边界之外的内容、不可见文本(白底白字或不可见渲染模式)或压缩伪影。能够可靠分析这些方面的工具对未来的研究将非常有价值。
工具和脚本
我们编写了一个脚本,该脚本使用pdfresurrectpdf和qpdf遍历当前工作目录中的所有 PDF 文件,并记录所有 PDF 版本之间的 PDF 对象差异。
例如,在文档“MHS 馆藏资产”中,脚本会记录以下条目:
1--- 差异开始:./MHS-collection-assets.pdf | 对象 16 (V1 vs V2) --- 2@@ -1 +1 @@ 3-<< /Annots 40 0 R /Contents 340 0 R /MediaBox [ 0 0 595.3200 841.9200 ] /Parent 1 0 R /Resources 335 0 R /Type /Page >> 4+<< /Annots 40 0 R /Contents 386 0 R /MediaBox [ 0 0 595.3200 841.9200 ] /Parent 1 0 R /Resources 383 0 R /Type /Page >> 5--- 差异结束:对象 16 ---
由此我们可以很快看出,在版本 1 和版本 2 之间,对象 16 上有一些内容变化。事实上,这就是我们在上一部分中讨论的章节删除是如何发现的。
对于大多数存在版本差异的文档,更改之处在于删除了制作人/作者元数据(例如,记者用来修改 PDF 文件的程序)。例如,以下是版本 1 和版本 2 之间删除的 ImageMagick Producer 和 Title 元数据:
1--- 差异开始:./tracking-targets-on-online-social-networks.pdf | 对象 297 (V1 vs V2) --- 2@@ -1 +1 @@ 3-<< /CreationDate (D:20150410150118) /ModDate (D:20150410150118) /Producer (ImageMagick 6.8.6-3 2014-04-08 Q16 http://www.imagemagick.org) /Title (Tracking Targets on Online Social Networks-final) >> 4+<< /CreationDate (D:20150410150118) /ModDate (D:20150410150118) >> 5--- 差异结束:对象 297 ---
许多文档在不同版本之间也存在页面旋转角度的变化。例如,此处页面顺时针旋转了 90 度:
1--- 差异开始:./operational-engineering-nov-2010.pdf | 对象 87(V1 与 V2)--- 2@@ -1 +1 @@ 3-<< /Contents 88 0 R /MediaBox [ 0 0 595.320 841.92 ] /Parent 1 0 R /Type /Page >> 4+<< /Contents 88 0 R /MediaBox [ 0 0 595.3200 841.9200 ] /Parent 1 0 R /Rotate 90 /Type /Page >> 5--- 差异结束:对象 87 ---
尤其有趣的是版本/Contents之间的/Resources变化,从中我们可以快速发现版本之间是否有实际内容发生了变化。
该工具pdfxplr能够很好地输出文档的基本元数据,例如作者、创建和修改日期、关键词、标题和版本数,但它还会尝试列出文档中找到的所有电子邮件、链接和 IP 地址。这对于一般的 PDF 取证用途可能很有用。然而,pdfxplr除了发现一些 NSA 特工的姓名和用户名之外,我们使用该工具并未发现任何有价值的信息。
该工具x-ray可以查找错误的编辑内容。它通过查找所有错误的编辑内容完成了任务。以下是“2010 年 5 月 28 日移动主题简报”文档的示例输出,其中显示实际文本被方框覆盖,因此文本实际上并未从 PDF 数据中删除:
1文件路径:./20140127-nyt-mobile_theme_briefing.pdf 2编辑数据: 3{ 4 "4": [ 5 { 6 "bbox": [ 7 83.9999771118164, 8 252.00003051757812, 9 695.9998779296875, 10 336.0 11 ], 12 "text": "\u2022\u202f独立地形,用于初始移动攻击 - SSE/SMO/COMSAT 接入(SSE 的长期 MVR)。" 13 } 14 ] 15}
注释、表格、附件
我们还检查了注释(使用PyMuPDF我们编写的脚本,详见此处)、表单字段(使用pypdf我们编写的脚本,详见此处)和附件(使用utilspdfdetach包中的脚本,详见此处)中是否存在隐藏数据。我们发现的注释全部由记者本人添加。在所有已发布的文档中,均未发现表单字段数据或嵌入文件。
我们的取证分析显示,大多数已发布的文档都得到了妥善处理,在数百份被检查的文档中,只有两份文档的版本历史记录存在明显的元数据泄露。主要发现(通过PDF版本控制暴露的有关NSA间谍中心的已删除内容)以及编辑框下可选择的文本,仅代表了这一专业出版流程中罕见的疏漏。
更普遍的问题是文档集中信息删减方式的不一致。相同的信息(例如代理用户名、目标标识符)经常在一个地方被删减,但在其他地方却清晰可见,有时甚至在同一份文档中也是如此。这种不一致性凸显了大规模人工审核的根本挑战——在处理数百份复杂的技术文档时,即使是细心的编辑也会遗漏细节。
总而言之,在当时的情况下,记者们的工作做得相当出色。痕迹依然存在,但微不足道。
如果分析已发表文档中的元数据泄露如此有趣,那么想象一下,在剩余的95%到99%的未发表文档中,我们又能发现什么呢?别着急,我们才等了十多年而已。
我们还不知道下一部分会涵盖什么内容,不过它可能与PDF取证完全无关,就像这部分和上一部分一样。